

News
US overtakes Chinese supercomputer to take top spot for fastest in the world
After a semi-annual assessment measuring supercomputer computational speeds, US-built IBM machine “Summit” has toppled two Chinese competitors to take the lead as the fastest of its kind in the world. China’s Tianhe-2 and Sunway TaihuLight spent the last two years at the top of the SuperComputer TOP500 List, but this month Summit pulled ahead of both with a performance of 143.5 quadrillion operations per second, making it 65% more powerful than the next non-US supercomputer on the list. Out of the top ten machines ranked, five are in the United States.
The TOP500 project was established in 1993 to track and rank meaningful statistics for organizations to use in determining their needs with regard to high-performance computing (HPC). The benchmark test used to determine the rankings is called “Linpack”, which requires HPC systems to solve a specific set of linear equations using floating point arithmetic. To help quantify just how powerful the machines in the HPC category are, Summit is 1 million times more powerful than the fastest laptop with 250 petabytes of storage capacity.
Located at the Oak Ridge Leadership Computing Facility (OCLF) in Tennessee, the Summit supercomputer has an architecture purpose-built and optimized by IBM for artificial intelligence. While specialized, access to its technology isn’t exclusive to the machine’s developers. All components are available to any enterprise as part of IBM’s product line.
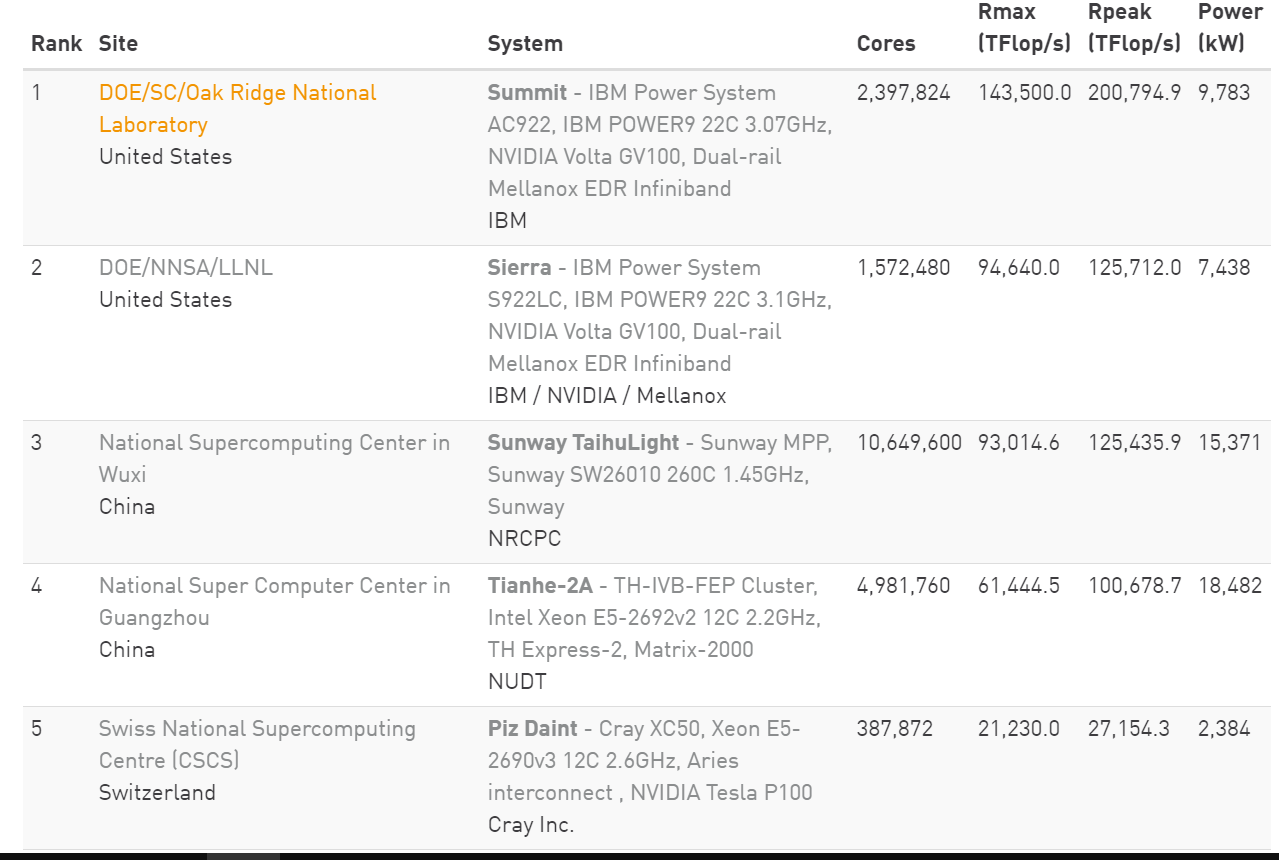
Summit was funded with part of a $258 million grant from the U.S. Department of Energy to help maintain US leadership in national security, manufacturing, industrial competitiveness, and energy and earth sciences. Summit’s “sister” computer, Sierra, was developed as part of the same Department of Energy commission and takes second place in the TOP500 list. This machine is located at Lawrence Livermore National Laboratory (LLNL) in California, and it boasts a computing speed of just under 95 quadrillion operations per second.
The HPC field overall provides computing power for advanced artificial intelligence along with massive data projects in business, medicine, science, and engineering. A recent competition hosted by the Association for Computing Machinery to recognize achievements in HPC, the Gordon Bell Prize, named five finalists that used Summit for advanced science research. The projects included, among others, an algorithm looking for genetic variations linked to complex traits and conditions such as opioid addiction, an AI simulation of earthquake physics in urban environments, and a deep neural network to identify extreme weather patterns from climate simulations. The winner of the competition will be named later this week at the 2018 International Conference for High Performance Computing, Networking, Storage, and Analysis in Dallas.
Watch the video below for more about Summit’s supercomputer capabilities.
Elon Musk
California snubs Tesla in its newly passed EV incentive that favors Rivian and Lucid
California passed a $135 million EV incentive that rewards Rivian and Lucid while sidelining Tesla

California just drew a line in the EV incentive sand to put Tesla on the wrong side of it. The state recently passed a $135 million program offering first-time electric vehicle buyers a direct incentive with no application required, but the rules were written in a way that leaves Tesla at a structural disadvantage compared to Rivian and Lucid.
The program caps eligible vehicles at $50,000 for new EVs and $25,000 for used ones. That pricing threshold rules out a significant portion of Tesla’s lineup, though some lower-priced Model 3 and Model Y configurations would still qualify. California-based automakers are exempt from the price cap entirely, regardless of what their vehicles cost. Rivian, headquartered in Irvine, and Lucid, based in the San Francisco Bay Area, both benefit from that exemption. Rivian’s R2 starts at roughly $45,000 but has versions above the cap. Lucid’s Air and Gravity start at $70,990 and $79,990 respectively, well above any threshold a non-California company would face.
California hits Tesla Cybercab and Robotaxi driverless cars with new law
Tesla built its reputation and a significant portion of its early market share in California, where EV adoption has consistently led the nation. The company operates its original factory in Fremont, California, and the state was home to Tesla’s headquarters for most of its existence. That changed in 2021 when Tesla moved its corporate headquarters to Austin, Texas. Since then, the relationship between the company and California Governor Gavin Newsom has been openly adversarial, with Musk and Newsom trading public criticism on multiple occasions.
California’s EV incentive landscape has shifted repeatedly in recent years, and Tesla has previously lost eligibility for state-level programs as its vehicles exceeded income-adjusted price thresholds. The federal $7,500 EV tax credit, which Tesla models have qualified for and lost depending on policy cycles, is no longer available after it expired without renewal, making state-level programs more meaningful to buyers than they have been in years.
The practical impact for buyers is more nuanced than the headline suggests. California residents purchasing a Tesla under $50,000 for the first time can still access the incentive. But the exemption written for California-based manufacturers is a structural advantage that rewards where a company plants its headquarters flag rather than where it builds its products, and Tesla moved that flag to Texas.
Elon Musk
SpaceX’s newest logo confirms everything about what it’s become
SpaceX officially absorbed xAI under the SpaceXAI brand, completing the largest private merger in history.

SpaceX made its corporate transformation official in May 2026 when Elon Musk posted on X that xAI would cease to exist as a standalone company. “xAI will be dissolved as a separate company, so it will just be SpaceXAI, the AI products from SpaceX,” he wrote.
A new SpaceXAI logo was announced today, visually embedding the xAI letters inside the SpaceX identity, which can be seen as a deliberate design choice that signals the merger is not a partnership but a full absorption and XAi a core function of the same company. The same way Starlink is not a separate brand but a SpaceX product. The announcement closed the loop on a process that began February 2, 2026, when SpaceX acquired xAI in the largest private merger in history, valued at $1.25 trillion. SpaceX at $1 trillion and xAI at $250 billion.
We are now @SpaceXAI. pic.twitter.com/ema66xDWC9
— SpaceXAI (@SpaceXAI) July 6, 2026
The reason SpaceX bought xAI was stated plainly by Musk at the time of the deal: to build orbital data centers. SpaceX had simultaneously filed with the FCC to launch up to one million satellites designed to function as AI compute nodes in low Earth orbit, escaping what Musk described as the energy constraints limiting AI development on Earth.
xAI provided the AI software stack, with Grok, the X platform, and the Colossus supercomputer infrastructure in Memphis with over 220,000 NVIDIA GPUs, while SpaceX provided the rockets, Starlink, and the capital base to fund it. The two companies needed each other. xAI was burning $2.5 billion in losses on $250 million in revenue. SpaceX was generating an estimated $8 billion in profit on $15 billion in revenue and needed an AI narrative to command the valuation it was targeting for its IPO.
What SpaceX has done, regardless of how the orbital AI vision ultimately plays out, is walk into a public market as something no company has been before: a rocket manufacturer, satellite internet provider, AI software company, social media platform, and supercomputer operator under one ticker. Whether that combination is worth $2 trillion depends entirely on which of those businesses you believe in most.

Tesla brought its innovative Cybercab robotaxi to the National Federation of the Blind (NFB) Annual Convention in Austin, Texas, on July 3 at the JW Marriott Austin.
The hands-on demonstration highlighted the vehicle’s thoughtful design for blind and visually impaired users, underscoring Tesla’s commitment to inclusive autonomous mobility. Attendees, many using white canes or accompanied by service dogs, experienced the steering-wheel-free Cybercab firsthand.
Cybercab at the National Federation of the Blind’s Annual Convention in Austin for a hands-on experience of its accessibility features for blind or visually impaired customers⁰⁰For example:⁰– Braille lettering on physical controls
– Space for service animals & assistive… pic.twitter.com/8wrJcDHkw7— Tesla Robotaxi (@robotaxi) July 6, 2026
The showcase emphasized practical features tailored to the needs of the blind community. Braille lettering appears on physical controls, including door releases and emergency buttons, allowing users to navigate interfaces independently through touch. Generous interior space accommodates service animals and assistive devices such as canes, guide dogs, or mobility aids without compromising comfort.
Wheelchair-height seating facilitates easier transfers for users with additional mobility challenges. Photos from the event captured blind attendees approaching the vehicle confidently, service dogs relaxing inside, and hands exploring Braille-equipped handles.
Tesla Robotaxi’s official account detailed these elements, noting the Cybercab’s focus on accessibility, especially noting the Braille lettering and additional space for service animals.
How Tesla Will Transform Mobility for the Blind
Autonomous vehicles like the Cybercab promise revolutionary independence for the roughly 2.2 million visually impaired Americans. Traditional barriers—reliance on sighted drivers, costly paratransit, or limited public transit—often restrict spontaneous travel. Tesla Full Self-Driving aims to eliminate the need for a human operator, enabling on-demand, door-to-door rides via simple app hailing with voice guidance.
Users gain freedom to work, socialize, shop, or attend events anytime without scheduling hassles or safety concerns. This reduces isolation, boosts employment opportunities, and enhances quality of life, turning mobility from a dependency into true personal autonomy.
The NFB demonstration not only gathered valuable feedback but also generated excitement about a future where technology levels the playing field. By prioritizing inclusive design, Tesla advances a vision of transportation that serves everyone, potentially reshaping daily life for blind individuals and setting a standard for the autonomous industry.
As Cybercab deployment scales, these accessibility innovations could mark a significant step toward equitable mobility.

California snubs Tesla in its newly passed EV incentive that favors Rivian and Lucid

SpaceX’s newest logo confirms everything about what it’s become





