News
SpaceX rocket catch simulation raises more questions about concept
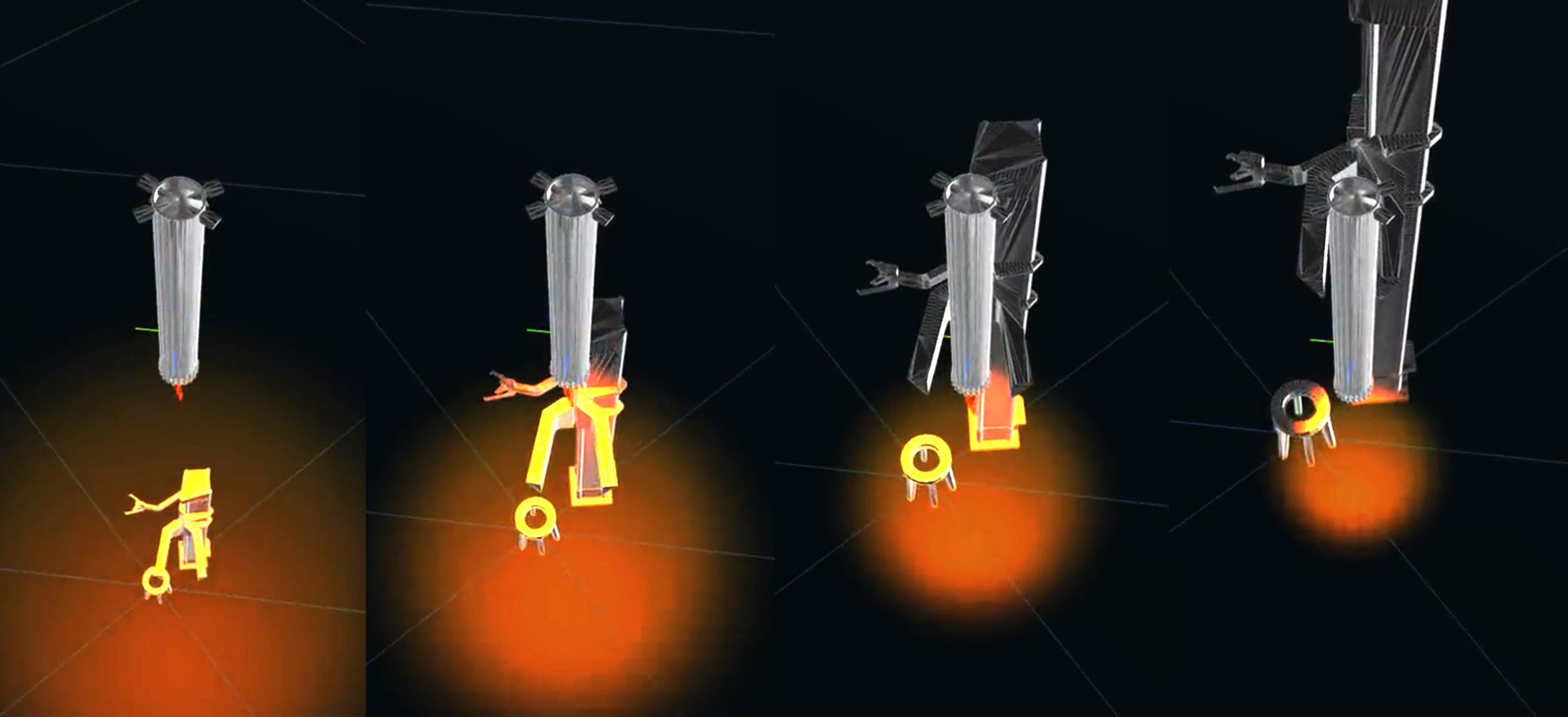
CEO Elon Musk has published the first official visualization of what SpaceX’s plans to catch Super Heavy boosters might look like in real life. However, the simulation he shared raises just as many questions as it answers.
Since at least late 2020, SpaceX CEO Elon Musk has been floating the idea of catching Starships and Super Heavy boosters out of the sky as an alternative to having the several-dozen-ton steel rockets use basic legs to land on the ground. This would be a major departure from SpaceX’s highly successful Falcon family, which land on a relatively complex set of deployable legs that can be retracted after most landings. The flexible, lightweight structures have mostly been reliable and easily reusable but Falcon boosters occasionally have rough landings, which can use up disposable shock absorbers or even damage the legs and make boosters hard to safely recover and slower to reuse.
As a smaller rocket, Falcon boosters have to be extremely lightweight to ensure healthy payload margins and likely weigh about 25-30 tons empty and 450 tons fully fueled – an excellent mass ratio for a reusable rocket. While it’s still good to continue that practice of rigorous mass optimization with Starship, the vehicle is an entirely different story. Once plans to stretch the Starship upper stage’s tanks and add three more Raptors are realized, it’s quite possible that Starship will be capable of launching more than 200 tons (~440,000 lb) of payload to low Earth orbit (LEO) with ship and booster recovery.
One might think that SpaceX, with the most capable rocket ever built potentially on its hands, would want to take advantage of that unprecedented performance to make the rocket itself – also likely to be one of the most complex launch vehicles ever – simpler and more reliable early on in the development process. Generally speaking, that would involve sacrificing some of its payload capability and adding systems that are heavier but simpler and more robust. Once Starship is regularly flying to orbit and gathering extensive flight experience and data, SpaceX might then be able refine the rocket, gradually reducing its mass and improving payload to orbit by optimizing or fully replacing suboptimal systems and designs.
Instead, SpaceX appears to be trying to substantially optimize Starship before it’s attempted a single orbital launch. The biggest example is Elon Musk’s plan to catch Super Heavy boosters – and maybe Starships, too – for the sole purpose of, in his own words, “[saving] landing leg mass [and enabling] immediate reflight of [a giant, unwieldy rocket].” Musk, SpaceX executives, or both appear to be attempting to refine a rocket that has never flown. Further, based on a simulation of a Super Heavy “catch” Musk shared on January 20th, all that oddly timed effort may end up producing a solution that’s actually worse than what it’s trying to replace.
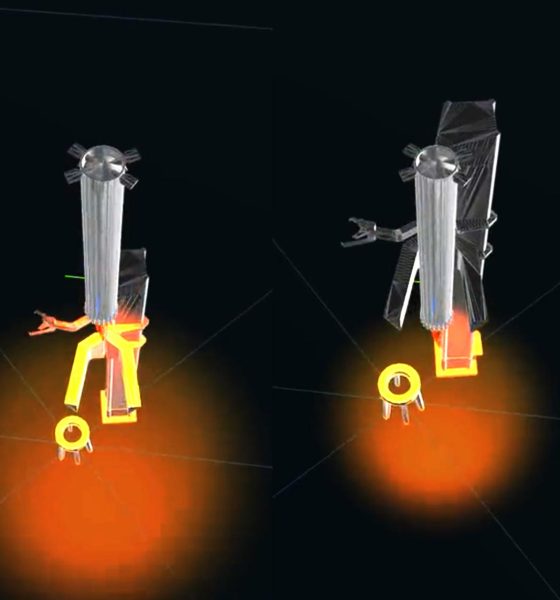
Based on the simulated telemetry shown in the visualization, Super Heavy’s descent to the landing zone appears to be considerably gentler than the ‘suicide burn’ SpaceX routinely uses on Falcon. By decelerating as quickly as possible and making landing burns as short as possible, Falcon saves a considerable amount of propellant during recovery – extra propellant that, if otherwise required, would effectively increase Falcon’s dry mass and decrease its payload to orbit. In the Super Heavy “catch” Musk shared, the booster actually appears to be landing – just on an incredibly small patch of steel on the tower’s ‘Mechazilla’ arms instead of a concrete pad on the ground.
Aside from a tiny bit of lateral motion, the arms appear motionless during the ‘catch,’ making it more of a landing. Further, Super Heavy is shown decelerating rather slowly throughout the simulation and appears to hover for almost 10 seconds near the end. That slow, cautious descent and even slower touchdown may be necessary because of how incredibly accurate Super Heavy has to be to land on a pair of hardpoints with inches of lateral margin for error and maybe a few square feet of usable surface area. The challenge is a bit like if SpaceX, for some reason, made Falcon boosters land on two elevated ledges about as wide as car tires. Aside from demanding accurate rotational control, even the slightest lateral deviation would cause the booster to topple off the pillars and – in the case of Super Heavy – fall about a hundred feet onto concrete, where it would obviously explode.
 -
-
What that slow descent and final hover mean is that the Super Heavy landing shown would likely cost significantly more delta V (propellant) than a Falcon-style suicide burn. Propellant has mass, so Super Heavy would likely need to burn at least 5-10 tons more to carefully land on arms that aren’t actively matching the booster’s position and velocity. Ironically, SpaceX could probably quite easily add rudimentary, fixed legs – removing most of the bad aspects of Falcon legs – to Super Heavy with a mass budget of 10 tons. But even if SpaceX were to make those legs as simple, dumb, and reliable as physically possible and they wound up weighing 20 tons total, the inherent physics of rocketry mean that adding 20 tons to Super Heavy’s likely 200-ton dry mass would only reduce the rocket’s payload to orbit by about 3-5 tons or 1-3%.
Further, per Musk’s argument that landing on the arms would enhance the speed of reuse, it’s difficult to see how landing Super Heavy or Starship in the exact same corridor – but on the ground instead of on the arms – would change anything. If Super Heavy is accurate enough to land on a few square meters of steel, it must inherently be accurate enough to land within the far larger breadth of those arms. The only process landing on the arms would clearly remove is reattaching the arms to a landed booster or ship, which it’s impossible to imagine would save more than a handful of minutes or maybe an hour of work. SpaceX’s Falcon booster turnaround record is currently 27 days, so it’s even harder to imagine why SpaceX would be worrying about cutting minutes or a few hours off of the turnaround and reuse of a rocket that has never even performed a full static fire test – let alone attempted an orbital-class launch, reentry, or landing.
Put simply, while Starbase’s launch tower arms will undoubtedly be useful for quickly lifting and stacking Super Heavy and Starship, it’s looking more and more likely that using those arms as a landing platform will, at best, be an inferior alternative to basic Falcon-style landings. More importantly, even if everything works perfectly, the arms actually cooperate with boosters to catch them, and it’s possible for Super Heavy to avoid hovering and use a more efficient suicide burn, the apparent best-case outcome of all that effort is marginally faster reuse and perhaps a 5% increase in payload to orbit. Only time will tell if such a radical change proves to be worth such marginal benefits.


Tesla has continued to flex the strength, rigidity, and robustness of its all-electric pickup, the Cybertruck. In fact, since 2019, Cybertruck’s ability to avoid dents, dings, and even gunfire has been one of the main selling points Tesla has used to attract buyers who are looking for a vehicle that can handle the most intense challenges.
But that does not mean Tesla is not still actively trying to make it even better.
In a new hardware update, Tesla has decided to change the material of the Cybertruck’s underbody panels from aluminum to carbon fiber, a move that aims to not only increase pricing efficiency but also improve strength.
RELATED:
Cybertruck Lead Engineer Wes Morrill confirmed the change was made to the Cybertruck recently after it was spotted by Coleton Guerin of Out of Spec. This particular trim level was a Cyberbeast, but it is being applied to all trims to keep supply chain efficiency high and have less variance across trim levels.
Morrill said that Tesla tested different materials for the underbody panel protection, and carbon fiber performed better than aluminum, which is what the company was using since its first deliveries in 2023.
Additionally, there are some efficiency improvements because Tesla can better form the areas around the bolts to keep underbody airflow cleaner than previously.
good eye – it’s a new material. Testing showed it to be more durable than the aluminum while being lower weight and cost. Also slight efficiency improvement since we can better form the areas around the bolts to keep the underbody airflow cleaner than what stamped aluminum allows
— Wes (@wmorrill3) July 30, 2026
Carbon fiber is traditionally lighter and more durable than aluminum, which is why it is such a popular material among luxury automakers, and EV makers will utilize some of the materials around battery packs to save weight.
This is the first instance of Tesla utilizing carbon fiber on the Cybertruck’s exterior to help with overall performance and strength. As previously mentioned, Tesla used aluminum to protect the underside of the body, but it is pretty typical for the company to continue making engineering changes that will improve the car in the future.

Tesla released Full Self-Driving version 14.3.7 yesterday, and after about 90 miles of testing today, it is evident there are some definite fixes from version 14.3.6, which I wrote about last week and called a regression.
Within the first 40 minutes of my drive on v14.3.7, it saved me from getting into an accident with an unaware Dodge Charger driver, and some of the things Tesla seemed to miss in v14.3.6 were definitely improved. All in all, the release so far has some really great performance, and I’m looking forward to testing it further.
For now, here’s everything I noticed with v14.3.7:
Overall Improvement
Just generally speaking from a ride perspective, this was a really great experience. A lot of the hesitancy I experienced on v14.3.6 was gone. There were no instances of brake-stabbing, wheel-jerking, or any uncertain or unconfident movements. It was void of anything that I felt made it timid with v14.3.6.
The one thing I do hope to see down the road is a smaller need to adjust Speed Profiles so often. Because Tesla calls FSD “Supervised,” I’m okay with needing to hit the scroll wheel a few times a drive.
However, I hope that things can be incrementally improved upon with speed. Sometimes it’s too fast; other times it’s too slow. It’s a difficult thing to hone in and refine, but I hope it eventually gets there.
I didn’t notice any significant left lane camping or any behaviors that were completely out of line. I am hopeful that this opinion does not change, but after driving a few days with this version and putting it in a variety of different situations, you are exposed to more behaviors, some of which are not necessarily what I’d prefer.
The big things to notice, at least in my experience thus far, are that the major issues with previous versions — meaning the braking stabbing and wheel jerking — simply weren’t there. That’s enough to already consider this progress compared to .6.
Manual Signal Override is More Responsive
On .6, I had quite a few issues with FSD ignoring my manually input turn signals. If Tesla wants to call it “Supervised,” then the car should not ignore any input the driver gives. If I touch the accelerator on FSD, the car speeds up.
🚨 Tesla FSD v14.3.7 obeying manual turn signals https://t.co/6eqToXpQfC pic.twitter.com/vHBlFQ4PDV
— TESLARATI (@Teslarati) August 2, 2026
The car did a great job of obeying my turn signals when I wanted it to change lanes, which is welcome.
Parking Lot Performance
Before .6, I traditionally took over in nearly every parking lot my car entered, because I knew it would not park somewhere that I wanted, and usually, it was just a tad too timid in this setting.
The one bright spot of .6 was how well it handled parking lots. This continued with v14.3.7:
I’m always really happy to see progress at all, but once parking preferences come to FSD, as long as this performance is still around, that could potentially be the biggest improvement I’ve seen in FSD in the year I’ve been using it personally on a daily basis.
Full Self-Driving Averts Disaster
A Dodge Charger changed into my lane without checking if I was there, running me off the road. FSD made the initial avoidance maneuver; I grabbed the wheel out of instinct, looked in my side mirror to ensure I had nobody following closely behind, hit the brake, and straightened the car back up to avoid a curb:
🚨 Guys this is why you all NEED to stay vigilant behind the wheel, even on Tesla Full Self-Driving
Human drivers are UNHINGED and have no idea what they’re doing anymore. This was a kid obviously younger than 20 years old with zero awareness.
First drive with v14.3.7 https://t.co/1vTbCMpCn8 pic.twitter.com/lz7KKEF6bj
— TESLARATI (@Teslarati) August 2, 2026
There have been quite a few responses to this video stating that I should never have grabbed the wheel. To be honest, I really wish I had not done so, because I do believe FSD would have avoided any sort of collision with anything, including the car or the curb.
However, this was the first time I had ever been this close to being hit while using FSD. My natural reaction was to take over. I think if I had had something like this happen before, my reaction might have been different.
Hitting the brake avoided hitting the curb, while FSD swerved to avoid the car. My concern after the car was clear of my front end was the curb. All in all, I’m really happy with how things turned out, and I think anyone could be a critic of how I handled it. I only had a split second to really make a decision, and thankfully, any damage was avoided.
It is clear FSD managed to avoid the car coming down before I was able to. I truly credit FSD for avoiding the collision.
What Needs to Improve
Better Recognition of Potholes, Uneven Roads, Sharp Changes in Roadway/Bumps
On Friday, my Fianceè and I were in the car, and FSD was driving us. We crossed over a roadway that has a traffic light, and FSD was traveling at 40 MPH on Standard, 5 MPH over the speed limit. Everything was more than reasonable.
However, the road we were crossing at the light has a major bump both as you start and finish crossing it. Without a speed reduction, your car can go airborne. The Tesla did just this on Friday on v14.3.6; it was an uncomfortable bounce that pretty much confirmed I would not ever let FSD go over again unless we were sitting at that intersection when there is a red light.
I even tried scrolling down into Sloth quickly, but I ended up just taking over:
This is that big bounce that I mentioned in the quoted post.
It’s just a tad too drastic to take at the speed FSD wants to go over it. You can see me quickly swipe down into Sloth, but I intervened. https://t.co/K20PK9ysBg pic.twitter.com/81Oc82ZJcZ
— TESLARATI (@Teslarati) August 2, 2026
A few people have said it remains related to the vision-based approach and its difficulty comprehending 3D. This is a huge issue because this can cause serious damage at certain speeds.
Navigation
Nothing new here. I still turn off “Online Routing” quite frequently to get the car to take logical routes from time to time.
Auto Wipers
Auto Wipers are just plain bad. I really hope Tesla just uses a rain sensor. I thought they had improved at one point, but I still get dry wipes, Speed 4 on a drizzle, and Speed 2 on a steady rain. In reality, these should be switched.
You can watch our full review of Tesla Full Self-Driving v14.3.7 below:
🚨 Tesla Full Self-Driving v14.3.7 saved me from an accident! FULL REVIEW: https://t.co/1vTbCMpCn8 pic.twitter.com/9mHmKVoMVA
— TESLARATI (@Teslarati) August 2, 2026

SpaceX will report second quarter results after the market closes on Tuesday, August 4, marking the first time the company has opened its books to the public since its record IPO in June. Management will host a live audio only webcast at 4:30 p.m. ET, streamed on X, with no dial in option.
The debut carries more weight than a typical first quarter as a public company. Two trading days after the release, on August 6, the first tranche of SpaceX’s lockup expires, freeing roughly 911.5 million insider and employee shares, worth well over $100 billion at current prices and the largest such release in Wall Street history. A second, larger tranche tied to the stock trading 30 percent above its $135 IPO price never triggered, since shares have spent most of July trading below that price.
Wall Street’s models point to revenue near $6.9 billion for the quarter, up sharply from the $4.69 billion SpaceX reported in the first quarter, with a narrower per share loss than the $1.27 posted three months earlier, according to estimates compiled by Motley Fool. Those numbers will be the first look at how SpaceX’s three segments, Starlink, launch and AI, are performing independently.
SpaceX scores another massive Pentagon deal to support military satellites
Investors heading into the call have a specific list of questions. How many net new Starlink subscribers did SpaceX add after ending March with 10.3 million, and is average revenue per user holding up as the service expands into lower income markets. How much of the AI segment’s revenue reflects contract signings with Anthropic, Google and Reflection AI this year, deals that combined could annualize to nearly $28 billion if fully ramped. Whether capital expenditures, which nearly doubled in the AI segment alone between 2024 and 2025, are still accelerating or starting to plateau. And whether management offers any forward guidance at all, something SpaceX has never done publicly.
The report will also land days after Elon Musk publicly denied a Wall Street Journal report describing internal planning to separate Tesla’s China business ahead of a potential Tesla-SpaceX merger. Whether Musk or SpaceX executives address that speculation on the call, even indirectly, maybe something investors will be listening for on Tuesday.
As Teslarati reported after Musk’s own warning to short sellers last week, the CEO has made clear he expects skeptics to be proven wrong over time. Tuesday will be the first chance for the numbers themselves to make that case.

Tesla quietly made the Cybertruck even stronger

Tesla Full Self-Driving v14.3.7 early review: FSD saved me from an accident





