Firmware
Tesla patent hints at Hardware 3’s neural network accelerator for faster processing
During the recently-held fourth-quarter earnings call, Elon Musk all but stated that Tesla holds a notable lead in the self-driving field. While responding to Loup Ventures analyst Gene Munster, who inquired about Morgan Stanley’s estimated $175 billion valuation for Waymo and its self-driving tech, Musk noted that Tesla actually has an advantage over other companies involved in the development of autonomous technologies, particularly when it comes to real-world miles.
“If you add everyone else up combined, they’re probably 5% — I’m being generous — of the miles that Tesla has. And this difference is increasing. A year from now, we’ll probably go — certainly from 18 months from now, we’ll probably have 1 million vehicles on the road with — that are — and every time the customers drive the car, they’re training the systems to be better. I’m just not sure how anyone competes with that,” Musk said.
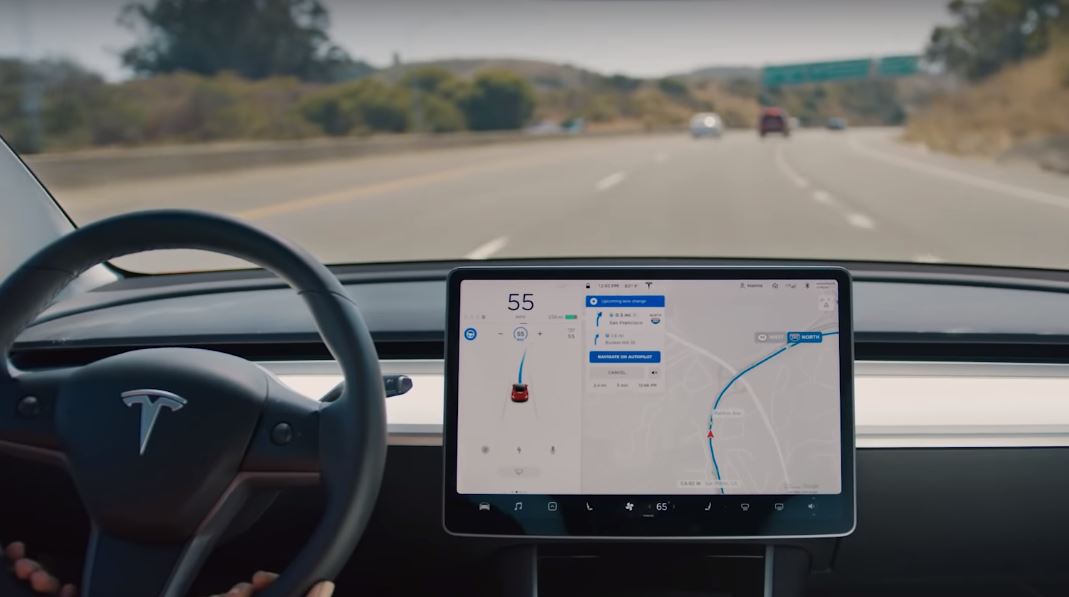
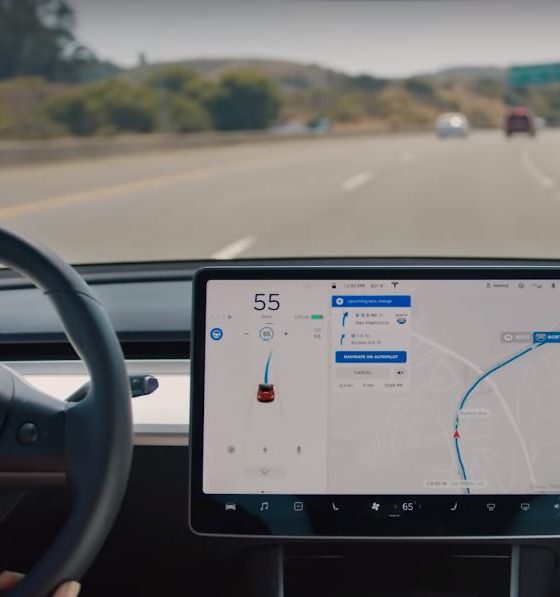
To carry its self-driving systems towards full autonomy, Tesla has been developing its custom hardware. Designed by Apple alumni Pete Bannon, Tesla’s Hardware 3 upgrade is expected to provide the company’s vehicles with a 1000% improvement in processing capability compared to current hardware. Tesla has released only a few hints about HW3’s capabilities over the past months. That said, a patent application from the electric car maker has recently been published by the US Patent Office, hinting at an “Accelerated Mathematical Engine” that would most likely be utilized for Tesla’s Hardware 3.

Tesla notes that there is a need to develop “high-computational-throughput systems and methods that can perform matrix mathematical operations quickly and efficiently,” particularly in computationally demanding applications such as convolutional neural networks (CNN), which are used in image recognition and processing. CNNs use deep learning to perform descriptive and generative tasks, usually utilizing machine vision that involves image and video recognition. These processes, which are invaluable for the development and operation of driver-assist systems like Autopilot, require a lot of computing power.
Considering the large amount of data involved in applications such as CNNs, the computational resources and the rate of calculations become limited by the capabilities of existing hardware. This becomes particularly evident in computing devices and processors that execute matrix operations, which encounter bottlenecks during heavy operations, resulting in wasted computing time. To address these limitations, Tesla’s patent application hints at the use of a custom matrix processor architecture.
“In operation according to certain embodiments, system 200 accelerates convolution operations by reducing redundant operations within the systems and implementing hardware specific logic to perform certain mathematical operations across a large set of data and weights. This acceleration is a direct result of methods (and corresponding hardware components) that retrieve and input image data and weights to the matrix processor 240 as well as timing mathematical operations within the matrix processor 240 on a large scale.”
By adopting its custom matrix processor architecture, Tesla expects its hardware to be capable of supporting larger amounts of data. In terms of formatting alone, the electric car maker notes that its design would allow the system to reformat data on the fly, making it immediately available for execution. Tesla also notes that its architecture would result in improvements in processing speed and efficiency.
“Unlike common software implementations of formatting functions that are performed by a CPU or GPU to convert a convolution operation into a matrix-multiply by rearranging data to an alternate format that is suitable for a fast matrix multiplication, various hardware implementations of the present disclosure re-format data on the fly and make it available for execution, e.g., 96 pieces of data every cycle, in effect, allowing a very large number of elements of a matrix to be processed in parallel, thus efficiently mapping data to a matrix operation. In embodiments, for 2N fetched input data 2N2 compute data may be obtained in a single clock cycle. This architecture results in a meaningful improvement in processing speeds by effectively reducing the number of read or fetch operations employed in a typical processor architecture as well as providing a paralleled, efficient and synchronized process in performing a large number of mathematical operations across a plurality of data inputs.”
It should be noted that Tesla’s patent application for its Accelerated Mathematical Engine is but one aspect of the company’s upcoming hardware upgrade to its fleet of electric cars. The full capabilities of Tesla’s Hardware 3, at least for now, remain to be seen. Ultimately, while Tesla did not provide concrete updates on the development and release of Hardware 3 to the company’s fleet of vehicles during the fourth quarter earnings call, Musk stated that some full self-driving features would likely be ready towards the end of 2019.
Back in October, Musk noted that Hardware 3 would be equipped in all new production cars in around 6 months, which translates to a rollout date of around April 2019. Musk stated that transitioning to the new hardware will not involve any changes with vehicle production, as the upgrade is simply a replacement of the Autopilot computer installed on all electric cars today. In a later tweet, Musk mentioned that Tesla owners who bought Full Self-Driving would receive the Hardware 3 upgrade free of charge. Owners who have not ordered Full Self-Driving, on the other hand, would likely pay around $5,000 for the FSD suite and the new hardware.
Tesla’s patent application for its Accelerated Mathematical Engine could be accessed here.
Elon Musk
Tesla confirmed HW3 can’t do Unsupervised FSD but there’s more to the story
Tesla confirmed HW3 vehicles cannot run unsupervised FSD, replacing its free upgrade promise with a discounted trade-in.
Tesla has officially confirmed that early vehicles with its Autopilot Hardware 3 (HW3) will not be capable of unsupervised Full Self-Driving, while extending a path forward for legacy owners through a discounted trade-in program. The announcement came by way of Elon Musk in today’s Tesla Q1 2026 earnings call.
🚨 Our LIVE updates on the Tesla Earnings Call will take place here in a thread 🧵
Follow along below: pic.twitter.com/hzJeBitzJU
— TESLARATI (@Teslarati) April 22, 2026
The history here matters. HW3 launched in April 2019, and Tesla sold Full Self-Driving packages to owners on the understanding that the hardware was sufficient for full autonomy. Some owners paid between $8,000 and $15,000 for FSD during that period. For years, as FSD’s AI models grew more demanding, HW3 vehicles fell progressively further behind, eventually landing on FSD v12.6 in January 2025 while AI4 vehicles moved to v13 and then v14. When Musk acknowledged in January 2025 that HW3 simply could not reach unsupervised operation, and alluded to a difficult hardware retrofit.
The near-term offering is more concrete. Tesla’s head of Autopilot Ashok Elluswamy confirmed on today’s call that a V14-lite will be coming to HW3 vehicles in late June, bringing all the V14 features currently running on AI4 hardware. That is a meaningful software update for owners who have been frozen at v12.6 for over a year, and it represents genuine effort to keep older hardware relevant. Unsupervised FSD for vehicles is now targeted for Q4 2026 at the earliest, with Musk describing it as a gradual, geography-limited rollout.
For HW3 owners, the over-the-air V14-lite update is welcomed, and the discounted trade-in path at least acknowledges an old obligation. What happens next with the trade-in pricing will define how this chapter ultimately gets written. If Tesla prices the hardware path fairly, acknowledges what early adopters are owed, and delivers V14-lite on the June timeline it committed to today, it has a real opportunity to convert one of the longest-running sore subjects among early adopters into a loyalty story.
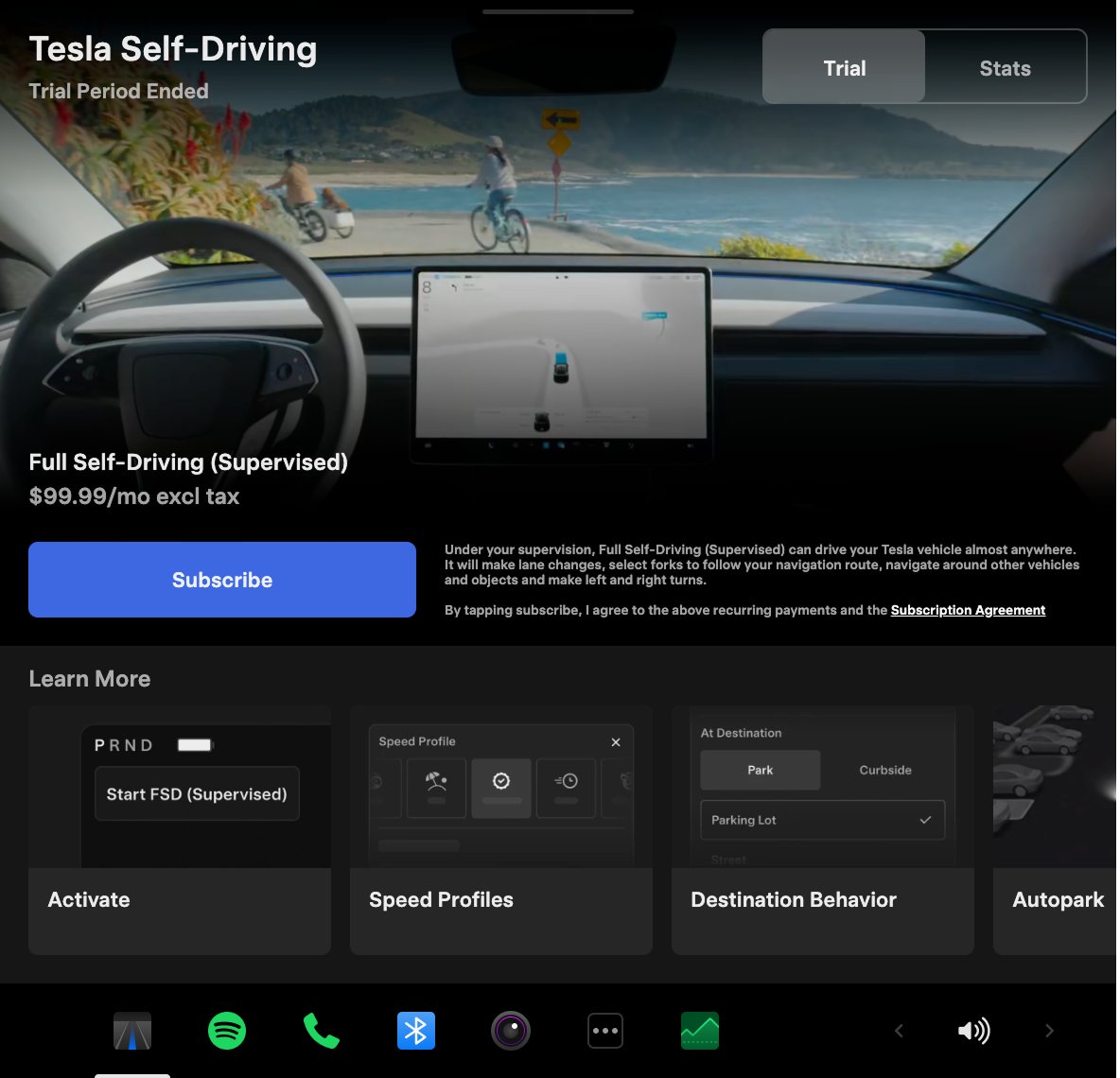
Tesla announced its Spring 2026 software update, and it’s the most feature-dense seasonal release the company has put out. The update covers twelve named changes spanning FSD, voice AI, safety lighting, dashcam storage, and pet display customization, among other things.
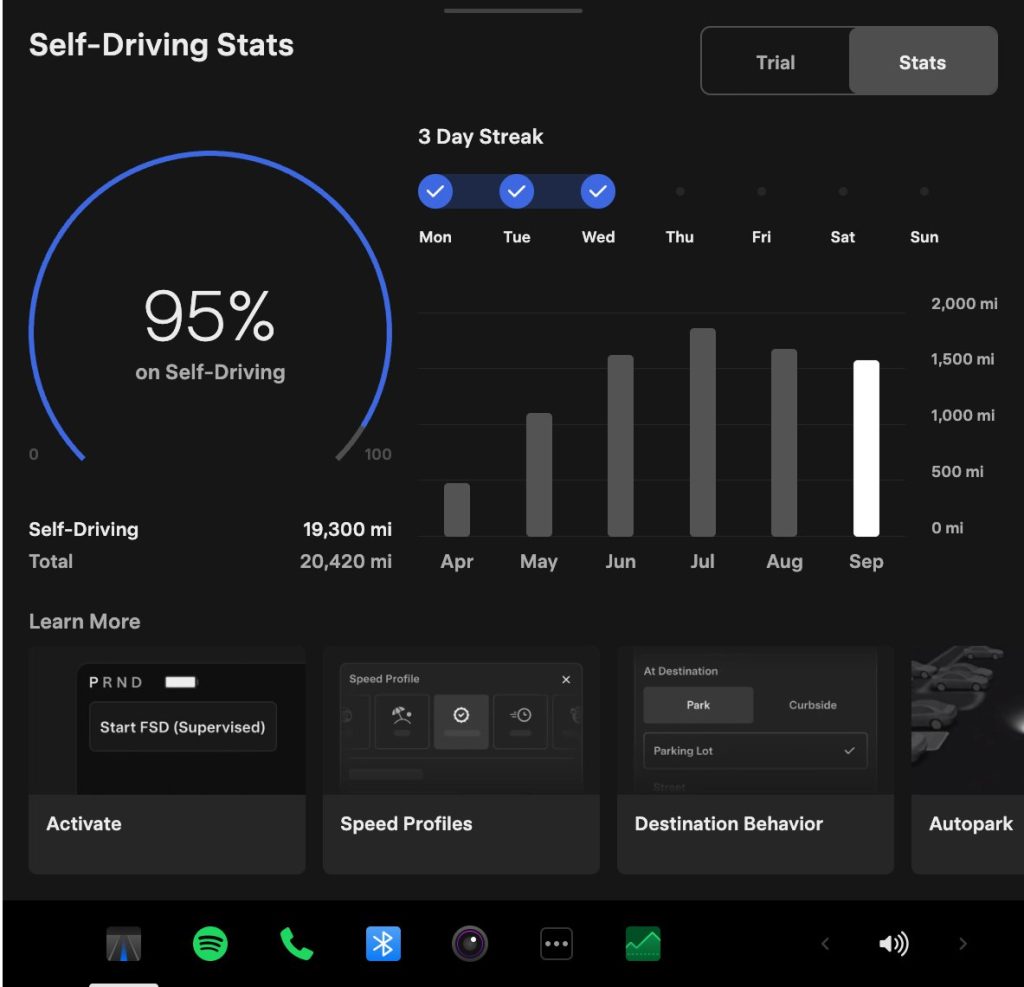
The centerpiece for owners with AI4 hardware is a redesigned Self-Driving app. The new interface lets owners subscribe to Full Self-Driving with a single tap and view ongoing FSD usage stats directly in the vehicle.
Grok gets its biggest in-car upgrade yet. The update adds a “Hey Grok” hands-free wake word along with location-based reminders, so a driver can now say “remind me to pick up groceries when I get home” without touching the screen. Grok first arrived in vehicles in July 2025, but each update has pushed it closer to genuine daily utility. Musk framed the broader vision clearly at Davos in January, saying Tesla is “really moving into a future that is based on autonomy.”
On safety, the update introduces enhanced blind spot warning lights that integrate directly with the cabin’s ambient lighting, building on the blind spot door warning that arrived in update 2026.8.

Dog Mode has been renamed Pet Mode and now lets owners choose a dog, cat, or hedgehog icon and add their pet’s name to the display.
Dashcam retention now extends up to 24 hours, up from the previous one-hour rolling loop, with a permanent save option for any clip. Weather maps now show rain and snow with better color differentiation and include the past hour of precipitation data along the route.
Tesla has now established a clear rhythm of two major OTA pushes per year. As with last year’s Spring update, that cycle started taking shape in 2025 with adaptive headlights and trunk customization. The 2025 Holiday Update then added Grok to the vehicle for the first time. This Spring follows that structure: the Holiday update introduces new architecture, and the Spring update broadens it across the fleet.
Two notable features still did not make it. IFTTT automations, which launched in China earlier this year, were held back from this North American release for unknown reasons, and Apple CarPlay remains absent, reportedly still delayed by iOS 26 and Apple Maps compatibility issues.
Below is the full list of feature updates released by Tesla.
— Tesla (@Tesla) April 13, 2026

It appears that Tesla may be preparing to roll out some subscription-based services soon. Based on the observations of a Wales-based Model 3 owner who performed some reverse-engineering on the Tesla mobile app, it seems that the electric car maker has added a new “Subscribe” option beside the “Buy” option within the “Upgrades” tab, at least behind the scenes.
A screenshot of the new option was posted in the r/TeslaMotors subreddit, and while the Tesla owner in question, u/Callump01, admitted that the screenshot looks like something that could be easily fabricated, he did submit proof of his reverse-engineering to the community’s moderators. The moderators of the r/TeslaMotors subreddit confirmed the legitimacy of the Model 3 owner’s work, further suggesting that subscription options may indeed be coming to Tesla owners soon.
Did some reverse engineering on the app and Tesla looks to be preparing for subscriptions? from r/teslamotors
Tesla’s Full Self-Driving suite has been heavily speculated to be offered as a subscription option, similar to the company’s Premium Connectivity feature. And back in April, noted Tesla hacker @greentheonly stated that the company’s vehicles already had the source codes for a pay-as-you-go subscription model. The Tesla hacker suggested then that Tesla would likely release such a feature by the end of the year — something that Elon Musk also suggested in the first-quarter earnings call. “I think we will offer Full Self-Driving as a subscription service, but it will be probably towards the end of this year,” Musk stated.
While the signs for an upcoming FSD subscription option seem to be getting more and more prominent as the year approaches its final quarter, the details for such a feature are still quite slim. Pricing for FSD subscriptions, for example, have not been teased by Elon Musk yet, though he has stated on Twitter that purchasing the suite upfront would be more worth it in the long term. References to the feature in the vehicles’ source code, and now in the Tesla mobile app, also listed no references to pricing.
The idea of FSD subscriptions could prove quite popular among electric car owners, especially since it would allow budget-conscious customers to make the most out of the company’s driver-assist and self-driving systems without committing to the features’ full price. The current price of the Full Self-Driving suite is no joke, after all, being listed at $8,000 on top of a vehicle’s cost. By offering subscriptions to features like Navigate on Autopilot with automatic lane changes, owners could gain access to advanced functions only as they are needed.
Elon Musk, for his part, has explained that ultimately, he still believes that purchasing the Full Self-Driving suite outright provides the most value to customers, as it is an investment that would pay off in the future. “I should say, it will still make sense to buy FSD as an option as in our view, buying FSD is an investment in the future. And we are confident that it is an investment that will pay off to the consumer – to the benefit of the consumer.” Musk said.

SpaceX adjusts Starship Flight 13 test launch target date once again

Elon Musk debunks $52 billion SpaceX-NVIDIA GPU deal






