
News
Google’s DeepMind unit develops AI that predicts 3D layouts from partial images
Google’s DeepMind unit, the same division that created AlphaGo, an AI that outplayed the best Go player in the world, has created a neural network capable of rendering an accurate 3D environment from just a few still images, filling in the gaps with an AI form of perceptual intuition.
According to Google’s official DeepMind blog, the goal of its recent AI project is to make neural networks easier and simpler to train. Today’s most advanced AI-powered visual recognition systems are trained through the use of large datasets comprised of images that are human-annotated. This makes training a very tedious, lengthy, and expensive process, as every aspect of every object in each scene in the dataset has to be labeled by a person.
The DeepMind team’s new AI, dubbed the Generative Query Network (GQN) is designed to remove this dependency on human-annotated data, as the GQN is designed to infer a space’s three-dimensional layout and features despite being provided with only partial images of a space.
Similar to babies and animals, DeepMind’s GQN learns by making observations of the world around it. By doing so, DeepMind’s new AI learns about plausible scenes and their geometrical properties even without human labeling. The GQN is comprised of two parts — a representation network that produces a vector describing a scene and a generation network that “imagines” the scene from a previously unobserved viewpoint. So far, the results of DeepMind’s training for the AI have been encouraging, with the GQN being able to create representations of objects and rooms based on just a single image.
As noted by the DeepMind team, however, the training methods that have been used for the development of the GQN are still limited compared to traditional computer vision techniques. The AI creators, however, remain optimistic that as new sources of data become available and as improvements in hardware get introduced, the applications for the GQN framework could move over to higher-resolution images of real-world scenes. Ultimately, the DeepMind team believes that the GQN could be a useful system in technologies such as augmented reality and self-driving vehicles by giving them a form of perceptual intuition – extremely desirable for companies focused on autonomy, like Tesla.
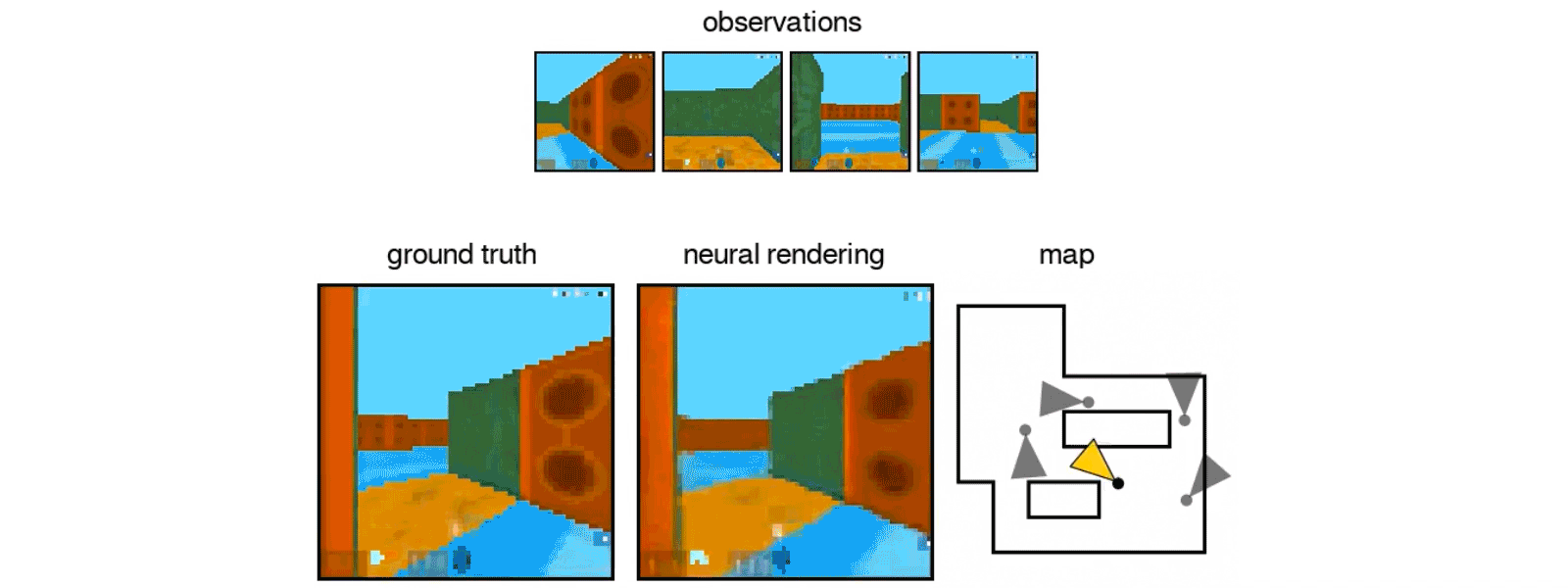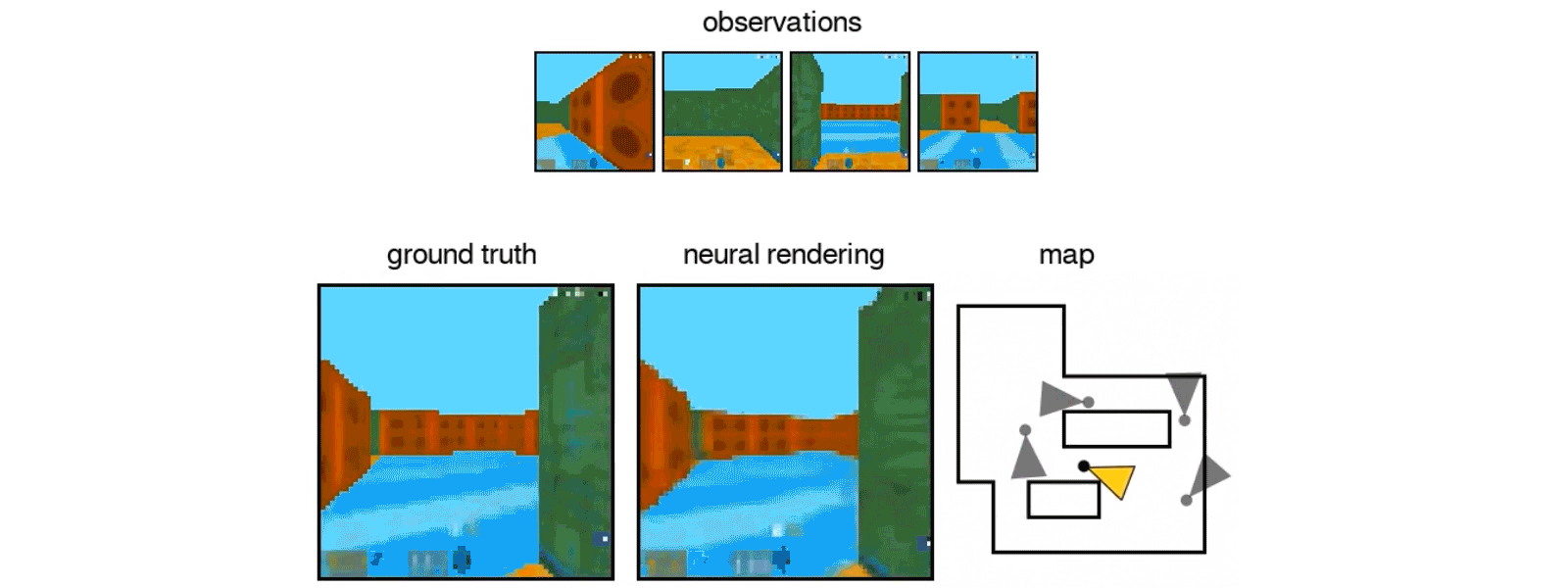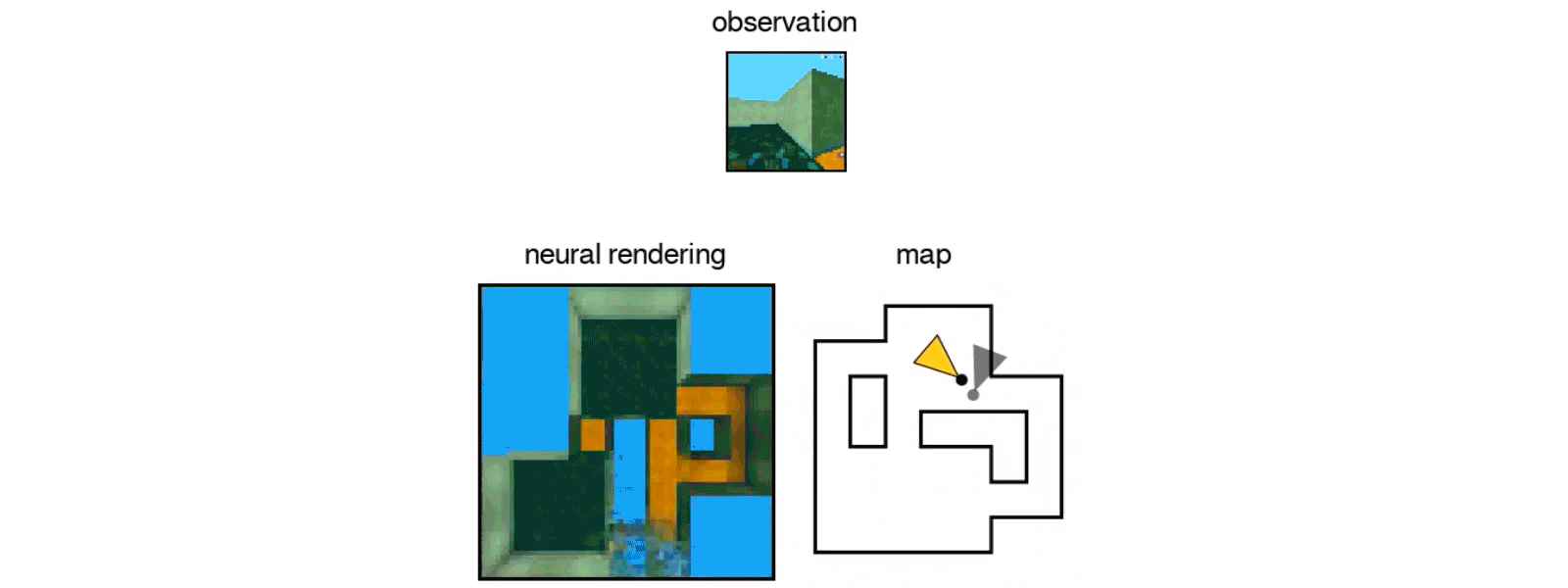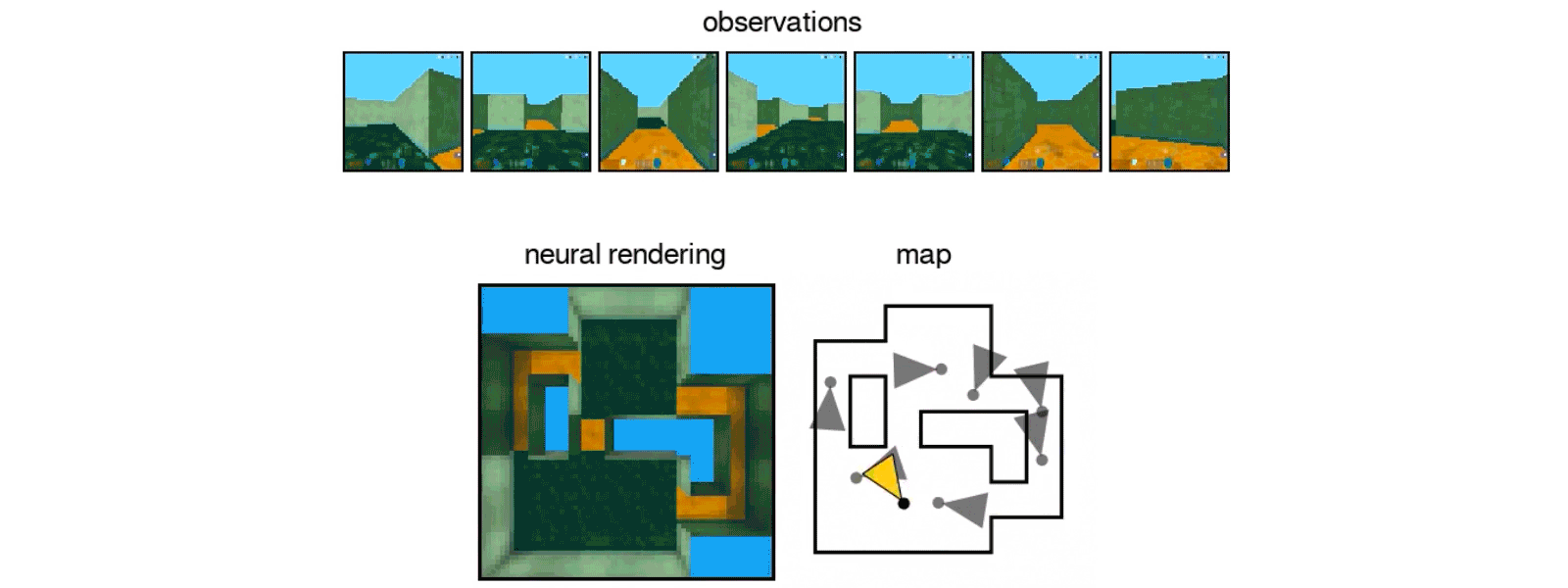
Google DeepMind’s GQN AI in action. [Credit: Google DeepMind]
In a talk at Train AI 2018 last May, Tesla’s head of AI Andrej Karpathy discussed the challenges involved in training the company’s Autopilot system. Tesla trains Autopilot by feeding the system with massive data sets from the company’s fleet of vehicles. This data is collected through means such as Shadow Mode, which allows the company to gather statistical data to show false positives and false negatives of Autopilot software.
During his talk, Karpathy discussed how features such as blinker detection become challenging for Tesla’s neural network to learn, considering that vehicles on the road have their turn signals off most of the time and blinkers have a high variability from one car brand to another. Karpathy also discussed how Tesla has transitioned a huge portion of its AI team to labeling roles, doing the human annotation that Google DeepMind explicitly wants to avoid with the GQN.
Musk also mentioned that its upcoming all-electric supercar — the next-generation Tesla Roadster — would feature an “Augmented Mode” that would enhance drivers’ capability to operate the high-performance vehicle. With Tesla’s flagship supercar seemingly set on embracing AR technology, the emergence of new techniques for training AI such as Google DeepMind’s GQN would be a perfect fit for the next generation of vehicles about to enter the automotive market.











News
These Tesla, X, and xAI engineers were just poached by OpenAI
The news is the latest in an ongoing feud between Elon Musk and the Sam Altman-run firm OpenAI.
OpenAI, the xAI competitor for which Elon Musk previously served as a boardmember and helped to co-found, has reportedly poached high-level engineers from Tesla, along with others from xAI, X, and still others.
On Tuesday, Wired reported that OpenAI hired four high-level engineers from Tesla, xAI, and X, as seen in an internal Slack message sent by co-founder Greg Brockman. The engineers include Tesla Vice President of Software Engineering David Lau, X and xAI’s head of infrastructure engineering Uday Ruddarraju, and fellow xAI infrastructure engineer Mike Dalton. The hiring spree also included Angela Fan, an AI researcher from Meta.
“We’re excited to welcome these new members to our scaling team,” said Hannah Wong, an OpenAI spokesperson. “Our approach is to continue building and bringing together world-class infrastructure, research, and product teams to accelerate our mission and deliver the benefits of AI to hundreds of millions of people.”
Lau has been in his position as Tesla’s VP of Software Engineering since 2017, after previously working for the company’s firmware, platforms, and system integration divisions.
“It has become incredibly clear to me that accelerating progress towards safe, well-aligned artificial general intelligence is the most rewarding mission I could imagine for the next chapter of my career,” Lau said in a statement to Wired.
🚨Optimistic projections point to xAI possibly attaining profitability by 2027, according to Bloomberg's sources.
If accurate, this would be quite a feat for xAI. OpenAI, its biggest rival, is still looking at 2029 as the year it could become cash flow positive.💰 https://t.co/pE5Z9daez8
— TESLARATI (@Teslarati) June 18, 2025
READ MORE ON OPENAI: Elon Musk’s OpenAI lawsuit clears hurdle as trial looms
At xAI, Ruddarraju and Dalton both played a large role in developing the Colossus supercomputer, which is comprised of over 200,000 GPUs. One of the major ongoing projects at OpenAI is the company’s Stargate program,
“Infrastructure is where research meets reality, and OpenAI has already demonstrated this successfully,” Ruddarraju told Wired in another statement. “Stargate, in particular, is an infrastructure moonshot that perfectly matches the ambitious, systems-level challenges I love taking on.”
Elon Musk is currently in the process of suing OpenAI for shifting toward a for-profit model, as well as for accepting an investment of billions of dollars from Microsoft. OpenAI retaliated with a counterlawsuit, in which it alleges that Musk is interfering with the company’s business and engaging in unfair competition practices.
Elon Musk confirms Grok 4 launch on July 9 with livestream event
News
SpaceX share sale expected to back $400 billion valuation
The new SpaceX valuation would represent yet another record-high as far as privately-held companies in the U.S. go.

A new report this week suggests that Elon Musk-led rocket company SpaceX is considering an insider share sale that would value the company at $400 billion.
SpaceX is set to launch a primary fundraising round and sell a small number of new shares to investors, according to the report from Bloomberg, which cited people familiar with the matter who asked to remain anonymous due to the information not yet being public. Additionally, the company would sell shares from employees and early investors in a follow-up round, while the primary round would determine the price for the secondary round.
The valuation would represent the largest in history from a privately-owned company in the U.S., surpassing SpaceX’s previous record of $350 billion after a share buyback in December. Rivaling company valuations include ByteDance, the parent company of TikTok, as well as OpenAI.
Bloomberg went on to say that a SpaceX representative didn’t respond to a request for comment at the time of publishing. The publication also notes that the details of such a deal could still change, especially depending on interest from the insider sellers and share buyers.
Axiom’s Ax-4 astronauts arriving to the ISS! https://t.co/WQtTODaYfj
— TESLARATI (@Teslarati) June 26, 2025
READ MORE ON SPACEX: SpaceX to decommission Dragon spacecraft in response to Pres. Trump war of words with Elon Musk
SpaceX’s valuation comes from a few different key factors, especially including the continued expansion of the company’s Starlink satellite internet company. According to the report, Starlink accounts for over half of the company’s yearly revenue. Meanwhile, the company produced its 10 millionth Starlink kit last month.
The company also continues to develop its Starship reusable rocket program, despite the company experiencing an explosion of the rocket on the test stand in Texas last month.
The company has also launched payloads for a number of companies and government contracts. In recent weeks, SpaceX launched Axiom’s Ax-4 mission, sending four astronauts to the International Space Station (ISS) for a 14-day stay to work on around 60 scientific experiments. The mission was launched using the SpaceX Falcon 9 rocket and a new Crew Dragon capsule, while the research is expected to span a range of fields including biology, material and physical sciences, and demonstrations of specialized technology.
News
Tesla Giga Texas continues to pile up with Cybercab castings
Tesla sure is gathering a lot of Cybercab components around the Giga Texas complex.

Tesla may be extremely tight-lipped about the new affordable models that it was expected to start producing in the first half of the year, but the company sure is gathering a lot of Cybercab castings around the Giga Texas complex. This is, at least, as per recent images taken of the facility.
Cybercab castings galore
As per longtime drone operator Joe Tegtmeyer, who has been chronicling the developments around the Giga Texas complex for several years now, the electric vehicle maker seems to be gathering hundreds of Cybercab castings around the factory.
Based on observations from industry watchers, the drone operator appears to have captured images of about 180 front and 180 rear Cybercab castings in his recent photos.
Considering the number of castings that were spotted around Giga Texas, it would appear that Tesla may indeed be preparing for the vehicle’s start of trial production sometime later this year. Interestingly enough, large numbers of Cybercab castings have been spotted around the Giga Texas complex in the past few months.
Cybercab production
The Cybercab is expected to be Tesla’s first vehicle that will adopt the company’s “unboxed” process. As per Tesla’s previous update letters, volume production of the Cybercab should start in 2026. So far, prototypes of the Cybercab have been spotted testing around Giga Texas, and expectations are high that the vehicle’s initial trial production should start this year.
With the start of Tesla’s dedicated Robotaxi service around Austin, it might only be a matter of time before the Cybercab starts being tested on public roads as well. When this happens, it would be very difficult to deny the fact that Tesla really does have a safe, working autonomous driving system, and it has the perfect vehicle for it, too.
These Tesla, X, and xAI engineers were just poached by OpenAI

SpaceX share sale expected to back $400 billion valuation

Tesla Giga Texas continues to pile up with Cybercab castings



-

 Elon Musk1 week ago
Elon Musk1 week agoTesla investors will be shocked by Jim Cramer’s latest assessment
-

 News2 weeks ago
News2 weeks agoTesla Robotaxi’s biggest challenge seems to be this one thing
-

 Elon Musk1 day ago
Elon Musk1 day agoElon Musk confirms Grok 4 launch on July 9 with livestream event
-

 News2 weeks ago
News2 weeks agoWatch the first true Tesla Robotaxi intervention by safety monitor
-

 News5 days ago
News5 days agoTesla Model 3 ranks as the safest new car in Europe for 2025, per Euro NCAP tests
-

 Elon Musk2 weeks ago
Elon Musk2 weeks agoA Tesla just delivered itself to a customer autonomously, Elon Musk confirms
-

 Elon Musk2 weeks ago
Elon Musk2 weeks agoxAI welcomes Memphis pollution results, environmental groups push back
-

 Elon Musk2 weeks ago
Elon Musk2 weeks agoElon Musk confirms Tesla Optimus V3 already uses Grok voice AI